
메타 AI에서 개발한 대규모 언어 모델인 Llama-3가 4월 18일 날 출시되었는데요
Llama-3 는 세 가지 모델 크기로 제공되었습니다
8B, 70B, 400B인데 400B는 아직 학습단계에 있다고 합니다.
이런 메타AI와 경쟁 중인 마이크로소프트가 고성능 생성형 인공지능 기술을
모바일 기기나 차량 등 더 많은 플랫폼으로 지원을 하기 위해서 확대하기 위해서
새로운 소형 언어 모델(SLM) Phi-3을 4월 24일에 발표를 해서 알아보게 되었습니다.
마이크로소프트는 Phi-3가 27억 개의 parameter를 이해할 수 있는 Phi-2 기반이며
최대 스물다섯배 더 큰 LLM 즉 대형 언어 모델만큼 성능이 뛰어나다고 발표를 했습니다.
파라미터는 언어 모델이 이해할 수 있는 복잡한 명령어의 수를 나타내는데요
예를 들어, 대형 언어 모델 중 하나인 오픈 AI의 GPT-4는 잠재적으로 1조 7,000억 개 이상의 parameter를 이해한다고 합니다.

Phi-3의 mini version이 3.8 billion 이니까 38억 개의 parameter로 이루어져 있는데요
small version과 medium version이 있는데 small version은 70억개로 mini verision에 비교해 약 2배 가까이고 medium version은 140억 개로 약 4배 가까이입니다. 그리고 GPT 3.5는 약 1750억 개의 parameter이니까 Phi-3는 굉장히 작은 모델이라고 할 수 있습니다.

이미 양자화된 Phi-3 미니 모델을 A16 바이오닉 칩이 기본적으로 실행되는 아이폰 14에 배포하여 성공적으로 테스트를 했다는데요
여기서 32비트가 아닌 4비트를 사용한 이유는 메모리 문제 때문이 큰데요 32비트를 사용하게 되면 DRAM이 15기가 정도가 필요한데 8분의 1 수준인 4비트를 사용해 1.8기가 램 ,
즉 아이폰 램의 30프로 정도만 사용해서 구동이 가능하다고 합니다.
위 사진은 아이폰 14에서 구동한 화면인데 초당 12토큰 이상을 생성하는 것을 시연한 화면입니다.
초당 12개의 단어가 나오니까 상당히 좋고 작은 크기에도 불구하고
이 모델은 학술 벤치마크와 내부 테스트를 통해 측정한 결과, 전반적 성능이 GPT-3.5에 필적했다고 밝혔습니다.
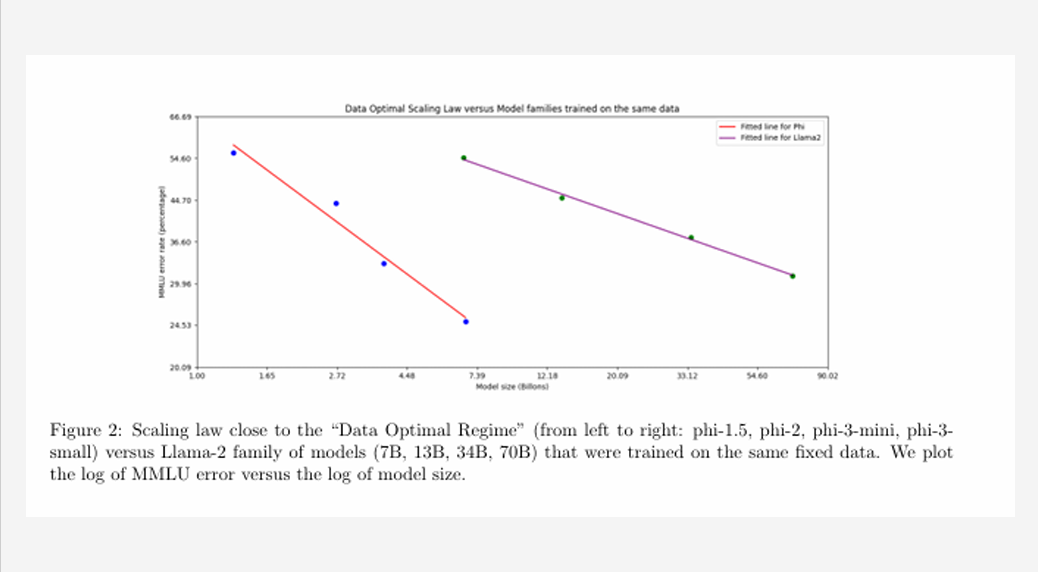
이건 이제 Phi-3 모델을 Llama-2 모델과 비교를 해본 건데요
세로축이 Error rate이고, 가로축이 모델 사이즈를 Billons단위인 그래프입니다.
빨간색 선에서 왼쪽부터 Phi-1.5, Phi-2, Phi-3 mini, Phi-small ver이고여
보라색 선은 왼쪽부터 Llama-2 7billion , 13 billion , 34 billion , 70 billion 순으로 비교한 겁니다.
보시다시피 Phi-3 small이 Llama-2 70 billion 보다 오류 가능성도 적으며 10분의 1 크기로 돌아가는 것을 확인할 수 있습니다.
즉 Llama-2가 훨씬 더 큰 모델임에도 불구하고 Phi-3 모델보다 효율성이 떨어진다는 것을 확인할 수 있었고,
Phi모델이 요점만 쏙속 뽑아내서 학습을 하기 때문에 이렇게 작은 크기로 성능이 잘 나오는 것 같습니다.
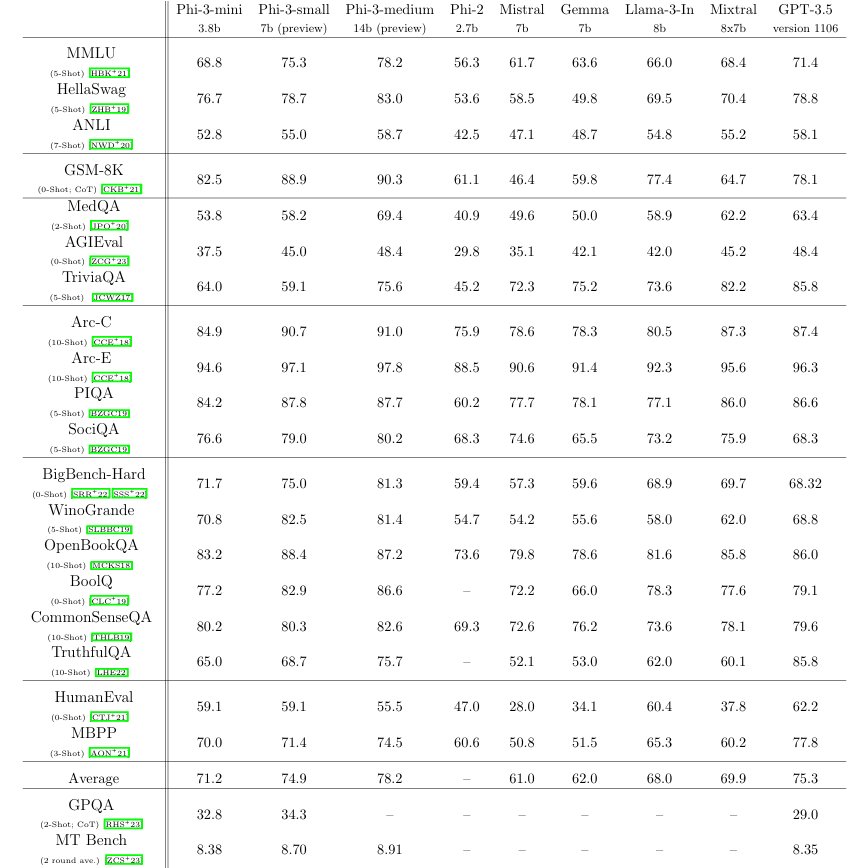
Chat GPT 3.5버전과 Llama 등 여러 비교군과 비교를 했는데
AI부분에선 벤치마크 수치로 성능을 비교하면 안 되고 사용성으로 평가를 해야 한다는 말이 나오고 있긴 하지만,
이렇게 작은 모델이 벤치마크 점수에서 Chat GPT 3.5와 비슷하거나 더 우수한 성능을 보인다는 게 놀라운 것 같습니다.

다음은 Phi-3 안정성에 관한 건데요
왼쪽 파란색 그래프는 safety post-training을 사용하지 않은 상태에서의 안정성이고
오른쪽 주황색 그래프는 safety post-training을 사용한 상태에서의 안정성을 의미합니다.

Phi - 3는 규모를 작게 하려다보니 실제 정보에 대한 부분이 약해질 수 있어서
검색과 결합을 해서 사실 정보를 다시 메우는 방법을 사용했습니다.
사진 왼쪽은 Phi - 3 mini에서 검색기능이 없었을 때 답변 사진인데
오른쪽 Phi - 3 mini 에서 검색기능을 이용했었을 때가 훨씬 더 자세한 것을 확인할 수 있습니다.

보고서 후반에 SLM이 즉 소형 언어 모델이 특정 장점을 가지고 있지만 단점도 있다고 인정을 했는데요
연구진은 Phi - 3가 대부분의 언어 모델과 마찬가지로 "사실적 부정확성(또는 환각), 편견의 재생산 또는 증폭, 부적절한 콘텐츠 생성, 안전 문제"에 여전히 직면을 해 있다고 지적했습니다.
또한 Phi - 3 mini는 훨씬 더 큰 모델과 언어 이해나 추론 수준이 비슷하지만, 작은 크기로 인해서 여전히 특정 작업에서는 크기로 인한 근본적 제약을 받는다”라고 한계가 있다고 설명을 하고 있습니다.
즉 Phi - 3 mini 는 많은 양의 "사실적 지식"을 저장할 수 있는 용량이 없지만, 검색 엔진과 페어링 해서 한계를 보완할 수 있다고 합니다.
미니 모델의 또 다른 약점은 대부분 언어를 영어로 제한했다는 점인데, 향후 작업에는 더 많은 다국어 데이터가 필요할 것이라고 합니다.
이런 단점들은 기존 모델보다 상당히 완화 되었지만 이러한 문제를 완전히 해결하기 위해 앞으로 상당한 작업이 남아 있다고 합니다.
'자기계발' 카테고리의 다른 글
| 강아지정보 페이지 (0) | 2024.09.10 |
|---|---|
| SPA & MPA 와 CSR & SSR 이란?? (0) | 2024.09.02 |
| 모던 자바스크립트 Deep Dive 13장 (0) | 2024.08.28 |
| 얼렁뚱땅 컴공과 데스크셋업 (0) | 2024.08.08 |
| 3만원으로 (개정) 정보처리산업기사 자격증 따기(필기 실기 합격후기) (0) | 2024.02.12 |



